Thinking Beyond Visibility: A Near-Optimal Policy Framework for Locally Interdependent Multi-Agent MDPs
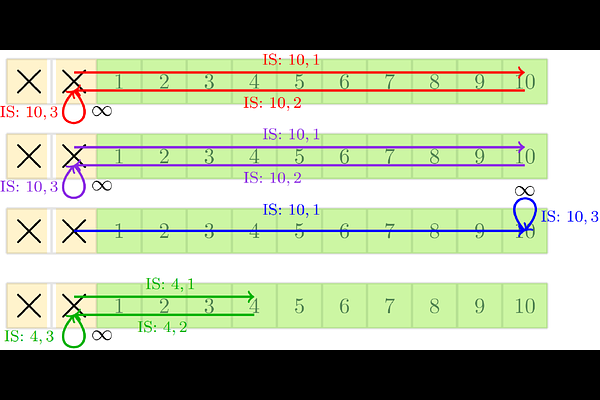
Thinking Beyond Visibility: A Near-Optimal Policy Framework for Locally Interdependent Multi-Agent MDPs
Alex DeWeese, Guannan Qu
AbstractDecentralized Partially Observable Markov Decision Processes (Dec-POMDPs) are known to be NEXP-Complete and intractable to solve. However, for problems such as cooperative navigation, obstacle avoidance, and formation control, basic assumptions can be made about local visibility and local dependencies. The work DeWeese and Qu 2024 formalized these assumptions in the construction of the Locally Interdependent Multi-Agent MDP. In this setting, it establishes three closed-form policies that are tractable to compute in various situations and are exponentially close to optimal with respect to visibility. However, it is also shown that these solutions can have poor performance when the visibility is small and fixed, often getting stuck during simulations due to the so called "Penalty Jittering" phenomenon. In this work, we establish the Extended Cutoff Policy Class which is, to the best of our knowledge, the first non-trivial class of near optimal closed-form partially observable policies that are exponentially close to optimal with respect to the visibility for any Locally Interdependent Multi-Agent MDP. These policies are able to remember agents beyond their visibilities which allows them to perform significantly better in many small and fixed visibility settings, resolve Penalty Jittering occurrences, and under certain circumstances guarantee fully observable joint optimal behavior despite the partial observability. We also propose a generalized form of the Locally Interdependent Multi-Agent MDP that allows for transition dependence and extended reward dependence, then replicate our theoretical results in this setting.