Pretrained Model Representations as Acquisition Signals for Active Learning of MLIPs
Pretrained Model Representations as Acquisition Signals for Active Learning of MLIPs
Eszter Varga-Umbrich, Shikha Surana, Paul Duckworth, Jules Tilly, Olivier Peltre, Zachary Weller-Davies
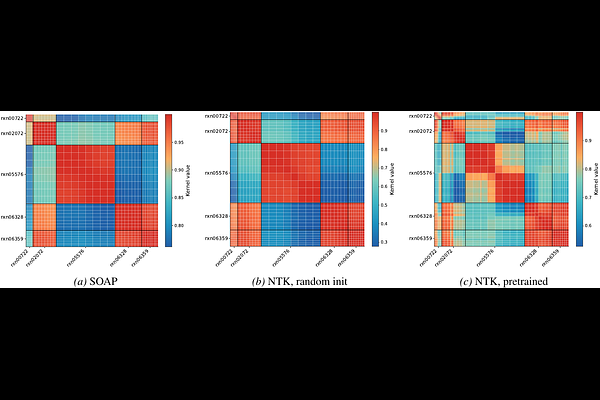
AbstractTraining machine learning interatomic potentials (MLIPs) for reactive chemistry is often bottlenecked by the high cost of quantum chemical labels and the scarcity of transition state configurations in candidate pools. Active learning (AL) can mitigate these costs, but its effectiveness hinges on the acquisition rule. We investigate whether the latent space of a pretrained MLIP already contains the information necessary for effective acquisition, eliminating the need for auxiliary uncertainty heads, Bayesian training and fine-tuning, or committee ensembles. We introduce two acquisition signals derived directly from a pretrained MACE potential: a finite-width neural tangent kernel (NTK) and an activation kernel built from hidden latent space features. On reactive-chemistry benchmarks, both kernels consistently outperform fixed-descriptor baselines, committee disagreement, and random acquisition, reducing the data required to reach performance targets by an average of 38% for energy error and 28% for force error. We further show that the pretrained model induces similarity spaces that preserve chemically meaningful structure and provide more reliable residual uncertainty estimates than randomly initialised or fixed-descriptor-based kernels. Our results suggest that pretraining aligns latent-space geometry with model error, yielding a practical and sufficient acquisition signal for reactive MLIP fine-tuning.