Refer to Anything with Vision-Language Prompts
Refer to Anything with Vision-Language Prompts
Shengcao Cao, Zijun Wei, Jason Kuen, Kangning Liu, Lingzhi Zhang, Jiuxiang Gu, HyunJoon Jung, Liang-Yan Gui, Yu-Xiong Wang
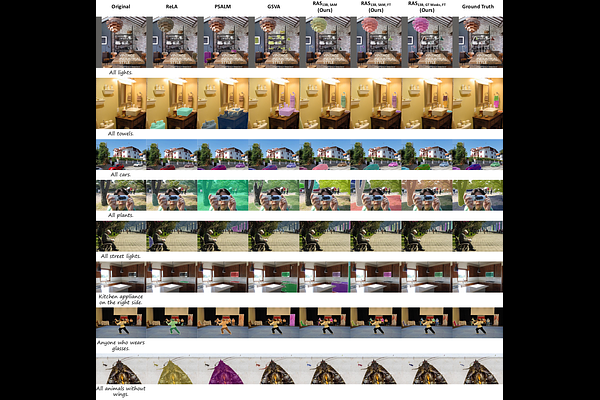
AbstractRecent image segmentation models have advanced to segment images into high-quality masks for visual entities, and yet they cannot provide comprehensive semantic understanding for complex queries based on both language and vision. This limitation reduces their effectiveness in applications that require user-friendly interactions driven by vision-language prompts. To bridge this gap, we introduce a novel task of omnimodal referring expression segmentation (ORES). In this task, a model produces a group of masks based on arbitrary prompts specified by text only or text plus reference visual entities. To address this new challenge, we propose a novel framework to "Refer to Any Segmentation Mask Group" (RAS), which augments segmentation models with complex multimodal interactions and comprehension via a mask-centric large multimodal model. For training and benchmarking ORES models, we create datasets MaskGroups-2M and MaskGroups-HQ to include diverse mask groups specified by text and reference entities. Through extensive evaluation, we demonstrate superior performance of RAS on our new ORES task, as well as classic referring expression segmentation (RES) and generalized referring expression segmentation (GRES) tasks. Project page: https://Ref2Any.github.io.