Imagine, Verify, Execute: Memory-Guided Agentic Exploration with Vision-Language Models
Imagine, Verify, Execute: Memory-Guided Agentic Exploration with Vision-Language Models
Seungjae Lee, Daniel Ekpo, Haowen Liu, Furong Huang, Abhinav Shrivastava, Jia-Bin Huang
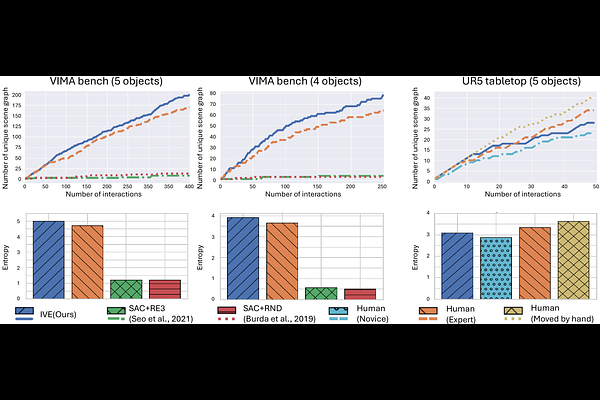
AbstractExploration is essential for general-purpose robotic learning, especially in open-ended environments where dense rewards, explicit goals, or task-specific supervision are scarce. Vision-language models (VLMs), with their semantic reasoning over objects, spatial relations, and potential outcomes, present a compelling foundation for generating high-level exploratory behaviors. However, their outputs are often ungrounded, making it difficult to determine whether imagined transitions are physically feasible or informative. To bridge the gap between imagination and execution, we present IVE (Imagine, Verify, Execute), an agentic exploration framework inspired by human curiosity. Human exploration is often driven by the desire to discover novel scene configurations and to deepen understanding of the environment. Similarly, IVE leverages VLMs to abstract RGB-D observations into semantic scene graphs, imagine novel scenes, predict their physical plausibility, and generate executable skill sequences through action tools. We evaluate IVE in both simulated and real-world tabletop environments. The results show that IVE enables more diverse and meaningful exploration than RL baselines, as evidenced by a 4.1 to 7.8x increase in the entropy of visited states. Moreover, the collected experience supports downstream learning, producing policies that closely match or exceed the performance of those trained on human-collected demonstrations.