Kinetics: Rethinking Test-Time Scaling Laws
Kinetics: Rethinking Test-Time Scaling Laws
Ranajoy Sadhukhan, Zhuoming Chen, Haizhong Zheng, Yang Zhou, Emma Strubell, Beidi Chen
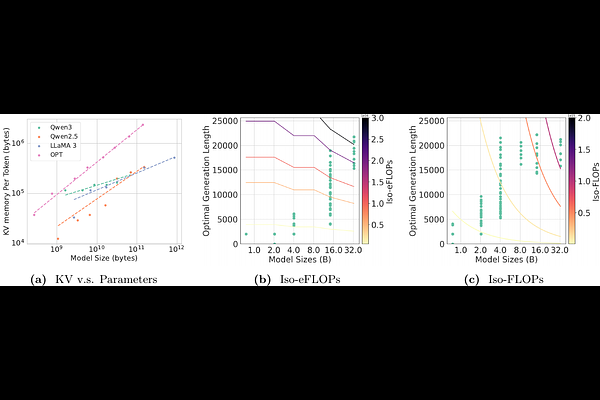
AbstractWe rethink test-time scaling laws from a practical efficiency perspective, revealing that the effectiveness of smaller models is significantly overestimated. Prior work, grounded in compute-optimality, overlooks critical memory access bottlenecks introduced by inference-time strategies (e.g., Best-of-$N$, long CoTs). Our holistic analysis, spanning models from 0.6B to 32B parameters, reveals a new Kinetics Scaling Law that better guides resource allocation by incorporating both computation and memory access costs. Kinetics Scaling Law suggests that test-time compute is more effective when used on models above a threshold than smaller ones. A key reason is that in TTS, attention, rather than parameter count, emerges as the dominant cost factor. Motivated by this, we propose a new scaling paradigm centered on sparse attention, which lowers per-token cost and enables longer generations and more parallel samples within the same resource budget. Empirically, we show that sparse attention models consistently outperform dense counterparts, achieving over 60 points gains in low-cost regimes and over 5 points gains in high-cost regimes for problem-solving accuracy on AIME, encompassing evaluations on state-of-the-art MoEs. These results suggest that sparse attention is essential for realizing the full potential of test-time scaling because, unlike training, where parameter scaling saturates, test-time accuracy continues to improve through increased generation. The code is available at https://github.com/Infini-AI-Lab/Kinetics.