EvoLM: Self-Evolving Language Models through Co-Evolved Discriminative Rubrics
EvoLM: Self-Evolving Language Models through Co-Evolved Discriminative Rubrics
Shuyue Stella Li, Rui Xin, Teng Xiao, Yike Wang, Rulin Shao, Zoey Hao, Melanie Sclar, Sewoong Oh, Faeze Brahman, Pang Wei Koh, Yulia Tsvetkov
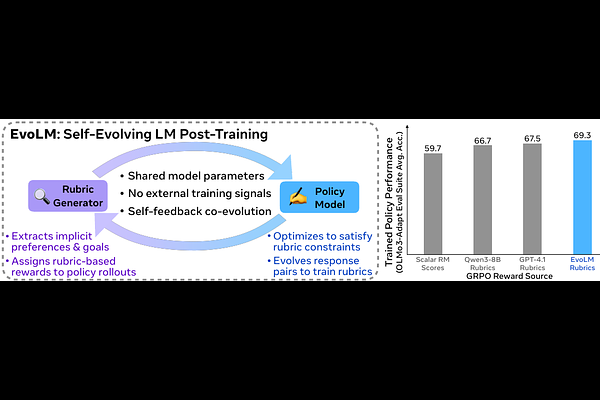
AbstractLanguage models encode substantial evaluative knowledge from pretraining, yet current post-training methods rely on external supervision (human annotations, proprietary models, or scalar reward models) to produce reward signals. Each imposes a ceiling. Human judgment cannot supervise capabilities beyond its own, proprietary APIs create dependencies, and verifiable rewards cover only domains with ground-truth answers. Self-improvement from a model's own evaluative capacity is a reward source that scales with the model itself, yet remains largely untapped by current methods. We introduce EVOLM, a post-training method that structures this capacity into explicit discriminative rubrics and uses them as training signal. EVOLM trains two capabilities within a single language model in alternation: (1) a rubric generator producing instance-specific evaluation criteria optimized for discriminative utility, which maximizes a small frozen judge's ability to distinguish preferred from dispreferred responses; and (2) a policy trained using those rubric-conditioned scores as reward. All preference signals are constructed from the policy's own outputs via temporal contrast with earlier checkpoints, requiring no human annotation or external supervision. EVOLM trains a Qwen3-8B model to generate rubrics that outperform GPT-4.1 on RewardBench-2 by 25.7%. The co-trained policy achieves 69.3% average on the OLMo3-Adapt suite, outperforming policies trained with GPT-4.1 prompted rubrics by 3.9% and with the state-of-the-art 8B reward model SkyWork-RM by 16%. Overall, EVOLM demonstrates that structuring a model's evaluative capacity into co-evolving discriminative rubrics enables self-improvement without external supervision.