Interpretability by Design for Efficient Multi-Objective Reinforcement Learning
Interpretability by Design for Efficient Multi-Objective Reinforcement Learning
Qiyue Xia, J. Michael Herrmann
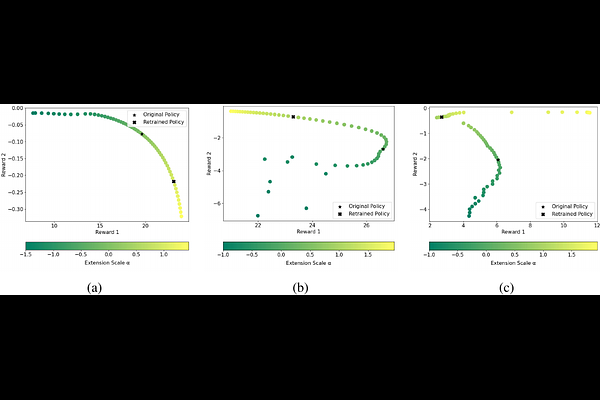
AbstractMulti-objective reinforcement learning (MORL) aims at optimising several, often conflicting goals in order to improve flexibility and reliability of RL in practical tasks. This can be achieved by finding diverse policies that are optimal for some objective preferences and non-dominated by optimal policies for other preferences so that they form a Pareto front in the multi-objective performance space. The relation between the multi-objective performance space and the parameter space that represents the policies is generally non-unique. Using a training scheme that is based on a locally linear map between the parameter space and the performance space, we show that an approximate Pareto front can provide an interpretation of the current parameter vectors in terms of the objectives which enables an effective search within contiguous solution domains. Experiments are conducted with and without retraining across different domains, and the comparison with previous methods demonstrates the efficiency of our approach.