ACE-Bench: Agent Configurable Evaluation with Scalable Horizons and Controllable Difficulty under Lightweight Environments
ACE-Bench: Agent Configurable Evaluation with Scalable Horizons and Controllable Difficulty under Lightweight Environments
Wang Yang, Chaoda Song, Xinpeng Li, Debargha Ganguly, Chuang Ma, Shouren Wang, Zhihao Dou, Yuli Zhou, Vipin Chaudhary, Xiaotian Han
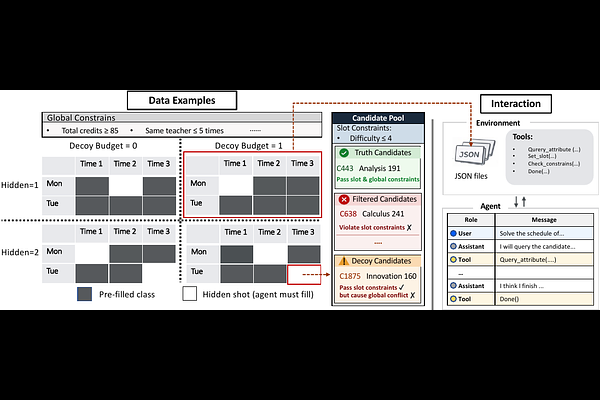
AbstractExisting Agent benchmarks suffer from two critical limitations: high environment interaction overhead (up to 41\% of total evaluation time) and imbalanced task horizon and difficulty distributions that make aggregate scores unreliable. To address these issues, we propose ACE-Bench built around a unified grid-based planning task, where agents must fill hidden slots in a partially completed schedule subject to both local slot constraints and global constraints. Our benchmark offers fine-grained control through two orthogonal axes: Scalable Horizons, controlled by the number of hidden slots $H$, and Controllable Difficulty, governed by a decoy budget $B$ that determines the number of globally misleading decoy candidates. Crucially, all tool calls are resolved via static JSON files under a Lightweight Environment design, eliminating setup overhead and enabling fast, reproducible evaluation suitable for training-time validation. We first validate that H and B provide reliable control over task horizon and difficulty, and that ACE-Bench exhibits strong domain consistency and model discriminability. We then conduct comprehensive experiments across 13 models of diverse sizes and families over 6 domains, revealing significant cross-model performance variation and confirming that ACE-Bench provides interpretable and controllable evaluation of agent reasoning.