Information Routing in Atomistic Foundation Models: How Equivariance Creates Linearly Disentangled Representations
Information Routing in Atomistic Foundation Models: How Equivariance Creates Linearly Disentangled Representations
Joshua Steier
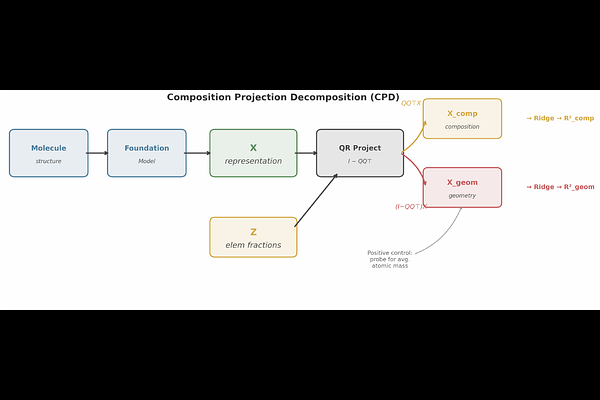
AbstractWhat do atomistic foundation models encode in their intermediate representations, and how is that information organized? We introduce Composition Projection Decomposition (CPD), which uses QR projection to linearly remove composition signal from learned representations and probes the geometric residual. Across eight models from five architectural families on QM9 molecules and Materials Project crystals, we find a disentanglement gradient: tensor product equivariant architectures (MACE) produce representations where geometry is almost fully linearly accessible after composition removal ($R^2_{\text{geom}} = 0.782$ for HOMO-LUMO gap), while handcrafted descriptors (ANI-2x) entangle the same information nonlinearly ($R^2_{\text{geom}} = -0.792$ under Ridge; $R^2 = +0.784$ under MLP). MACE routes target-specific signal through irreducible representation channels -- dipole to $L = 1$, HOMO-LUMO gap to $L = 0$ -- a pattern not observed in ViSNet's vector-scalar architecture under the same probe. We show that gradient boosted tree probes on projected residuals are systematically inflated, recovering $R^2 = 0.68$--$0.95$ on a purely compositional target, and recommend linear probes as the primary metric. Linearly disentangled representations are more sample-efficient under linear probing, suggesting a practical advantage for equivariant architectures beyond raw prediction accuracy.