SMIET: Fast and accurate synthesis of radio pulses from extensive air shower using simulated templates
SMIET: Fast and accurate synthesis of radio pulses from extensive air shower using simulated templates
Mitja Desmet, Keito Watanabe, Tim Huege, Stijn Buitink
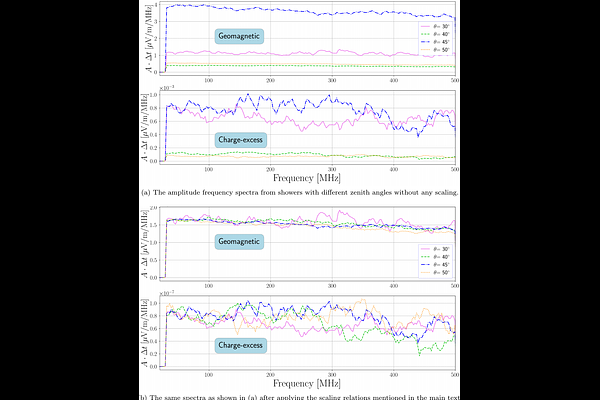
AbstractInterpreting the data from radio detectors for extensive air showers typically relies on Monte-Carlo based simulation codes, which, despite their accuracy are computationally expensive and present bottlenecks for analyses. To address this issue we developed a novel method called template synthesis, which synthesises the radio emission from cosmic ray air showers in seconds. This hybrid approach uses a microscopically simulated, sliced shower (the origin) as an input. It rescales the emission from each slice individually to synthesise the emission from a shower with different properties (the target). In order to be able to change the arrival direction during synthesis, we adjust the phases based on the expected geometrical delays. We benchmark the method by comparing synthesised traces to CoREAS simulations over a wide frequency range of [30, 500] MHz . The synthesis quality is primarily influenced by the difference in $X_{max}$ between the origin and target shower. When $\Delta X_{max} \leq 100 g/cm^2$ , the scatter on the maximum amplitudes of the geomagnetic traces is at most 4%. For the traces from the charge-excess component this scatter is smaller than 6%. We also observe a bias with $\Delta X_{max}$ up to 5% for both components, which appears to depend on the antenna position. Since the bias is symmetrical around $\Delta X_{max} = 0 g/cm^2$, we can use an interpolation approach to correct for it. We have implemented the template synthesis algorithm in a Python package called \texttt{SMIET}, which includes all the necessary parameters. This package has been successfully tested with air showers with zenith angles up to $50^{\circ}$ and can be used with any atmosphere, observation level and magnetic field. We demonstrate that the synthesis quality remains comparable to our main benchmarks across various scenarios and discuss use cases, including machine-learning-based analyses.