From Complex Dynamics to DynFormer: Rethinking Transformers for PDEs
From Complex Dynamics to DynFormer: Rethinking Transformers for PDEs
Pengyu Lai, Yixiao Chen, Dewu Yang, Rui Wang, Feng Wang, Hui Xu
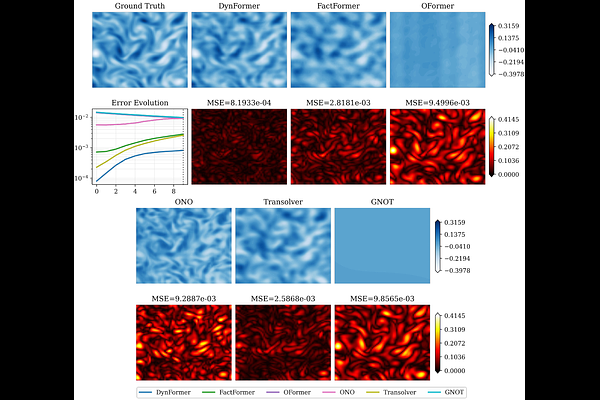
AbstractPartial differential equations (PDEs) are fundamental for modeling complex physical systems, yet classical numerical solvers face prohibitive computational costs in high-dimensional and multi-scale regimes. While Transformer-based neural operators have emerged as powerful data-driven alternatives, they conventionally treat all discretized spatial points as uniform, independent tokens. This monolithic approach ignores the intrinsic scale separation of physical fields, applying computationally prohibitive global attention that redundantly mixes smooth large-scale dynamics with high-frequency fluctuations. Rethinking Transformers through the lens of complex dynamics, we propose DynFormer, a novel dynamics-informed neural operator. Rather than applying a uniform attention mechanism across all scales, DynFormer explicitly assigns specialized network modules to distinct physical scales. It leverages a Spectral Embedding to isolate low-frequency modes, enabling a Kronecker-structured attention mechanism to efficiently capture large-scale global interactions with reduced complexity. Concurrently, we introduce a Local-Global-Mixing transformation. This module utilizes nonlinear multiplicative frequency mixing to implicitly reconstruct the small-scale, fast-varying turbulent cascades that are slaved to the macroscopic state, without incurring the cost of global attention. Integrating these modules into a hybrid evolutionary architecture ensures robust long-term temporal stability. Extensive memory-aligned evaluations across four PDE benchmarks demonstrate that DynFormer achieves up to a 95% reduction in relative error compared to state-of-the-art baselines, while significantly reducing GPU memory consumption. Our results establish that embedding first-principles physical dynamics into Transformer architectures yields a highly scalable, theoretically grounded blueprint for PDE surrogate modeling.