MASSV: Multimodal Adaptation and Self-Data Distillation for Speculative Decoding of Vision-Language Models
MASSV: Multimodal Adaptation and Self-Data Distillation for Speculative Decoding of Vision-Language Models
Mugilan Ganesan, Shane Segal, Ankur Aggarwal, Nish Sinnadurai, Sean Lie, Vithursan Thangarasa
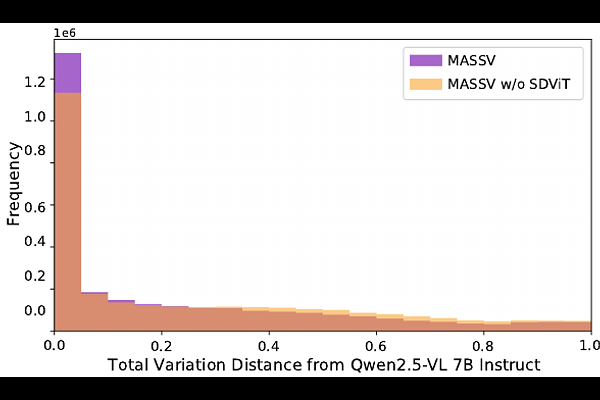
AbstractSpeculative decoding significantly accelerates language model inference by enabling a lightweight draft model to propose multiple tokens that a larger target model verifies simultaneously. However, applying this technique to vision-language models (VLMs) presents two fundamental challenges: small language models that could serve as efficient drafters lack the architectural components to process visual inputs, and their token predictions fail to match those of VLM target models that consider visual context. We introduce Multimodal Adaptation and Self-Data Distillation for Speculative Decoding of Vision-Language Models (MASSV), which transforms existing small language models into effective multimodal drafters through a two-phase approach. MASSV first connects the target VLM's vision encoder to the draft model via a lightweight trainable projector, then applies self-distilled visual instruction tuning using responses generated by the target VLM to align token predictions. Comprehensive experiments across the Qwen2.5-VL and Gemma3 model families demonstrate that MASSV increases accepted length by up to 30% and delivers end-to-end inference speedups of up to 1.46x on visually-grounded tasks. MASSV provides a scalable, architecture-compatible method for accelerating both current and future VLMs.