QKVShare: Quantized KV-Cache Handoff for Multi-Agent On-Device LLMs
QKVShare: Quantized KV-Cache Handoff for Multi-Agent On-Device LLMs
Pratik Honavar, Tejpratap GVSL
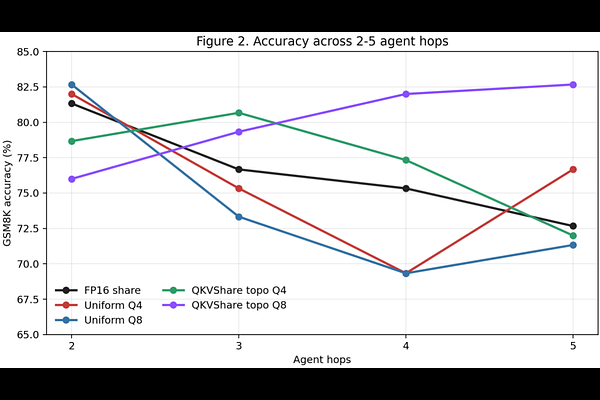
AbstractMulti-agent LLM systems on edge devices need to hand off latent context efficiently, but the practical choices today are expensive re-prefill or full-precision KV transfer. We study QKVShare, a framework for quantized KV-cache handoff between agents that combines token-level mixed-precision allocation, a self-contained CacheCard representation, and a HuggingFace-compatible cache injection path. Our current results support a narrower but clearer story than the original draft: on 150 GSM8K problems with Llama-3.1-8B-Instruct, adaptive quantization remains competitive under repeated handoff and shows its clearest gains against uniform quantization in deeper-hop, higher budget settings; for handoff latency, the QKVShare path reduces TTFT relative to full re prefill at every tested context, from 130.7 ms vs. 150.2 ms at nominal 1K context to 397.1 ms vs. 1029.7 ms at nominal 8K context;. Stage timing shows that post-injection generation, not card creation, dominates the current QKVShare latency path. These results position quantized KV handoff as a promising on-device systems direction while also highlighting the need for stronger controller ablations and apples-to-apples runtime comparisons.