Phi-4-reasoning-vision-15B Technical Report
Phi-4-reasoning-vision-15B Technical Report
Jyoti Aneja, Michael Harrison, Neel Joshi, Tyler LaBonte, John Langford, Eduardo Salinas
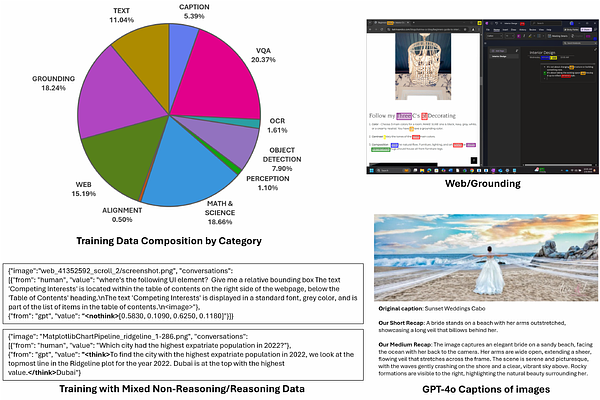
AbstractWe present Phi-4-reasoning-vision-15B, a compact open-weight multimodal reasoning model, and share the motivations, design choices, experiments, and learnings that informed its development. Our goal is to contribute practical insight to the research community on building smaller, efficient multimodal reasoning models and to share the result of these learnings as an open-weight model that is good at common vision and language tasks and excels at scientific and mathematical reasoning and understanding user interfaces. Our contributions include demonstrating that careful architecture choices and rigorous data curation enable smaller, open-weight multimodal models to achieve competitive performance with significantly less training and inference-time compute and tokens. The most substantial improvements come from systematic filtering, error correction, and synthetic augmentation -- reinforcing that data quality remains the primary lever for model performance. Systematic ablations show that high-resolution, dynamic-resolution encoders yield consistent improvements, as accurate perception is a prerequisite for high-quality reasoning. Finally, a hybrid mix of reasoning and non-reasoning data with explicit mode tokens allows a single model to deliver fast direct answers for simpler tasks and chain-of-thought reasoning for complex problems.