Preserving Plasticity in Continual Learning with Adaptive Linearity Injection
Preserving Plasticity in Continual Learning with Adaptive Linearity Injection
Seyed Roozbeh Razavi Rohani, Khashayar Khajavi, Wesley Chung, Mo Chen, Sharan Vaswani
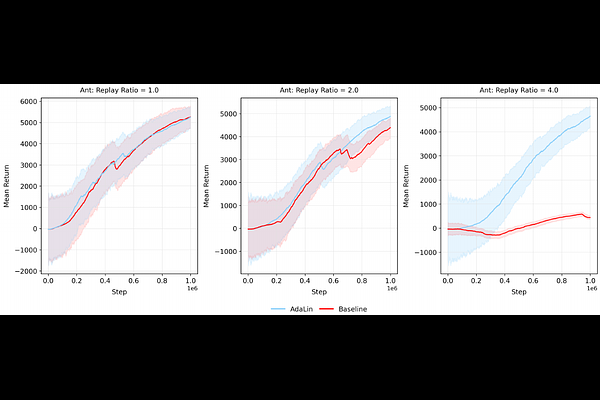
AbstractLoss of plasticity in deep neural networks is the gradual reduction in a model's capacity to incrementally learn and has been identified as a key obstacle to learning in non-stationary problem settings. Recent work has shown that deep linear networks tend to be resilient towards loss of plasticity. Motivated by this observation, we propose Adaptive Linearization (AdaLin), a general approach that dynamically adapts each neuron's activation function to mitigate plasticity loss. Unlike prior methods that rely on regularization or periodic resets, AdaLin equips every neuron with a learnable parameter and a gating mechanism that injects linearity into the activation function based on its gradient flow. This adaptive modulation ensures sufficient gradient signal and sustains continual learning without introducing additional hyperparameters or requiring explicit task boundaries. When used with conventional activation functions like ReLU, Tanh, and GeLU, we demonstrate that AdaLin can significantly improve performance on standard benchmarks, including Random Label and Permuted MNIST, Random Label and Shuffled CIFAR-10, and Class-Split CIFAR-100. Furthermore, its efficacy is shown in more complex scenarios, such as class-incremental learning on CIFAR-100 with a ResNet-18 backbone, and in mitigating plasticity loss in off-policy reinforcement learning agents. We perform a systematic set of ablations that show that neuron-level adaptation is crucial for good performance and analyze a number of metrics in the network that might be correlated to loss of plasticity.