SPAT: Sensitivity-based Multihead-attention Pruning on Time Series Forecasting Models
SPAT: Sensitivity-based Multihead-attention Pruning on Time Series Forecasting Models
Suhan Guo, Jiahong Deng, Mengjun Yi, Furao Shen, Jian Zhao
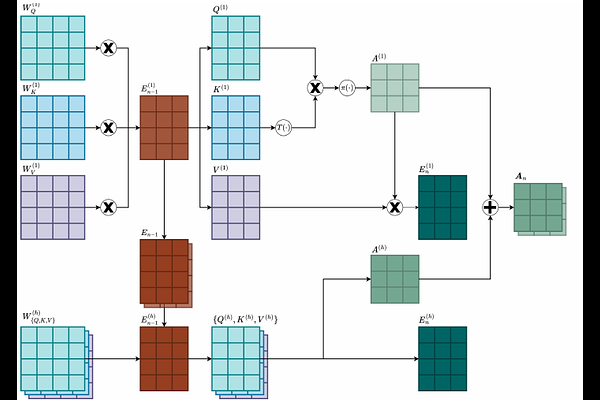
AbstractAttention-based architectures have achieved superior performance in multivariate time series forecasting but are computationally expensive. Techniques such as patching and adaptive masking have been developed to reduce their sizes and latencies. In this work, we propose a structured pruning method, SPAT ($\textbf{S}$ensitivity $\textbf{P}$runer for $\textbf{At}$tention), which selectively removes redundant attention mechanisms and yields highly effective models. Different from previous approaches, SPAT aims to remove the entire attention module, which reduces the risk of overfitting and enables speed-up without demanding specialized hardware. We propose a dynamic sensitivity metric, $\textbf{S}$ensitivity $\textbf{E}$nhanced $\textbf{N}$ormalized $\textbf{D}$ispersion (SEND) that measures the importance of each attention module during the pre-training phase. Experiments on multivariate datasets demonstrate that SPAT-pruned models achieve reductions of 2.842% in MSE, 1.996% in MAE, and 35.274% in FLOPs. Furthermore, SPAT-pruned models outperform existing lightweight, Mamba-based and LLM-based SOTA methods in both standard and zero-shot inference, highlighting the importance of retaining only the most effective attention mechanisms. We have made our code publicly available https://anonymous.4open.science/r/SPAT-6042.