Correct Is Not Enough: Training Reasoning Planners with Executor-Grounded Rewards
Correct Is Not Enough: Training Reasoning Planners with Executor-Grounded Rewards
Tianyang Han, Hengyu Shi, Junjie Hu, Xu Yang, Zhiling Wang, Junhao Su
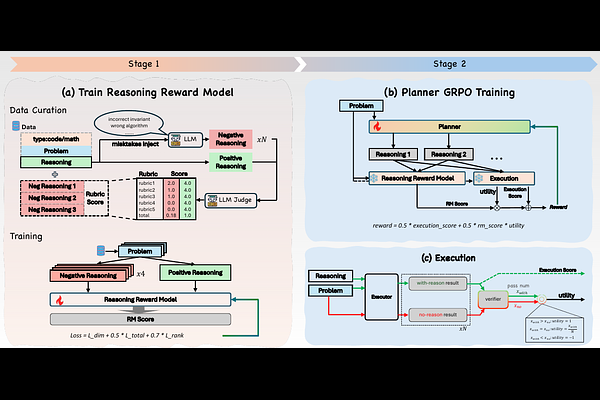
AbstractReinforcement learning with verifiable rewards has become a common way to improve explicit reasoning in large language models, but final-answer correctness alone does not reveal whether the reasoning trace is faithful, reliable, or useful to the model that consumes it. This outcome-only signal can reinforce traces that are right for the wrong reasons, overstate reasoning gains by rewarding shortcuts, and propagate flawed intermediate states in multi-step systems. To this end, we propose TraceLift, a planner-executor training framework that treats reasoning as a consumable intermediate artifact. During planner training, the planner emits tagged reasoning. A frozen executor turns this reasoning into the final artifact for verifier feedback, while an executor-grounded reward shapes the intermediate trace. This reward multiplies a rubric-based Reasoning Reward Model (RM) score by measured uplift on the same frozen executor, crediting traces that are both high-quality and useful. To make reasoning quality directly learnable, we introduce TRACELIFT-GROUPS, a rubric-annotated reason-only dataset built from math and code seed problems. Each example is a same-problem group containing a high-quality reference trace and multiple plausible flawed traces with localized perturbations that reduce reasoning quality or solution support while preserving task relevance. Extensive experiments on code and math benchmarks show that this executor-grounded reasoning reward improves the two-stage planner-executor system over execution-only training, suggesting that reasoning supervision should evaluate not only whether a trace looks good, but also whether it helps the model that consumes it.