Forgetting in Language Models: Capacity, Optimization, and Self-Generated Replay
Forgetting in Language Models: Capacity, Optimization, and Self-Generated Replay
Martin Marek, Dongkyu Cho, Shikai Qiu, Rumi Chunara, Pavel Izmailov, Andrew Gordon Wilson
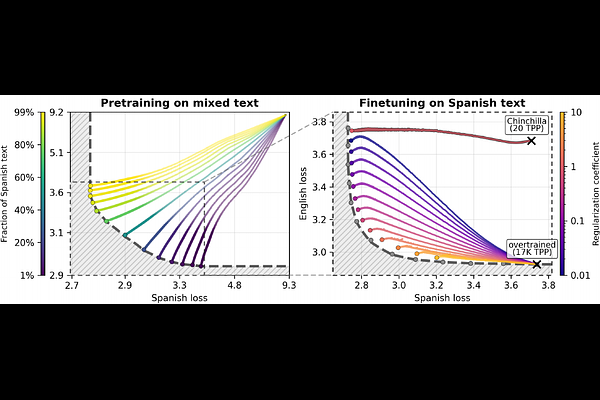
AbstractModels trained on a new task typically degrade on prior tasks, a phenomenon known as forgetting. Traditionally, mitigating forgetting has required replaying stored exemplars from prior tasks, which is often impractical. By contrast, language models can sample from their own training distribution, and we show that these self-generated samples serve as effective replay data, nearly eliminating forgetting. We find that forgetting nonetheless persists when the model has little remaining capacity: models pretrained close to saturation cannot absorb new information without overwriting prior knowledge. When capacity is not the limiting factor, low learning rates reduce forgetting but require substantially more training steps. Replay breaks this tradeoff, enabling fast, high-learning-rate finetuning without forgetting.