FADRM: Fast and Accurate Data Residual Matching for Dataset Distillation
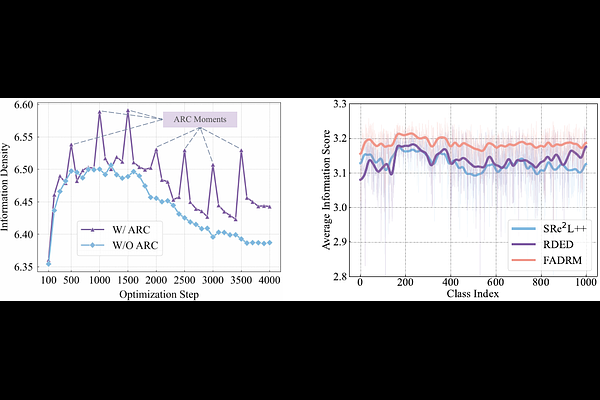
FADRM: Fast and Accurate Data Residual Matching for Dataset Distillation
Jiacheng Cui, Xinyue Bi, Yaxin Luo, Xiaohan Zhao, Jiacheng Liu, Zhiqiang Shen
AbstractResidual connection has been extensively studied and widely applied at the model architecture level. However, its potential in the more challenging data-centric approaches remains unexplored. In this work, we introduce the concept of Data Residual Matching for the first time, leveraging data-level skip connections to facilitate data generation and mitigate data information vanishing. This approach maintains a balance between newly acquired knowledge through pixel space optimization and existing core local information identification within raw data modalities, specifically for the dataset distillation task. Furthermore, by incorporating optimization-level refinements, our method significantly improves computational efficiency, achieving superior performance while reducing training time and peak GPU memory usage by 50%. Consequently, the proposed method Fast and Accurate Data Residual Matching for Dataset Distillation (FADRM) establishes a new state-of-the-art, demonstrating substantial improvements over existing methods across multiple dataset benchmarks in both efficiency and effectiveness. For instance, with ResNet-18 as the student model and a 0.8% compression ratio on ImageNet-1K, the method achieves 47.7% test accuracy in single-model dataset distillation and 50.0% in multi-model dataset distillation, surpassing RDED by +5.7% and outperforming state-of-the-art multi-model approaches, EDC and CV-DD, by +1.4% and +4.0%. Code is available at: https://github.com/Jiacheng8/FADRM.