PauLIB: A High-Performance Library for Processing Pauli Strings
PauLIB: A High-Performance Library for Processing Pauli Strings
Florian Krötz
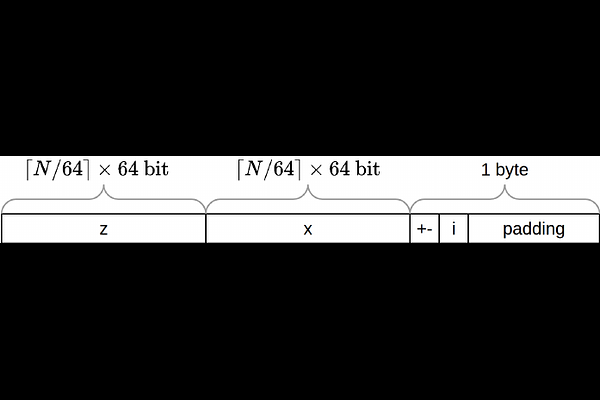
AbstractProcessing large Pauli sums is a significant bottleneck in quantum chemistry, Pauli propagation, and Pauli-based compilation. Existing frameworks often suffer from Python interpreter overhead or utilize hash-map data structures that hinder SIMD vectorization and complicate multi-threaded merging. We present PauLIB, a header-only C++20 library designed to eliminate these bottlenecks through three key architectural choices. A bit-packed binary symplectic representation that encodes each qubit in two bits, reducing Pauli multiplication to a bitwise XOR and a population count; a sorted array layout that replaces hash maps to enable branch-predictable SIMD bulk operations; and a struct-of-arrays (SoA) memory layout that exposes contiguous word arrays for explicit SIMD vectorization. Benchmarks at 500 qubits show that single Pauli string multiplication runs at 25ns per operation-14 times faster than PauliEngine and 660 times faster than Qiskit-flat across all pair counts tested. Hamiltonian outer-product multiplication is approximately 10 times faster than PauliEngine and 45 times faster than Qiskit at all tested sizes. Greedy commutation grouping, the dominant preprocessing cost in variational algorithms, achieves up to 21,000 times speedup over PennyLane, driven by the compact bit-packed representation. The compact layout reduces the memory footprint of a one-million-term Hamiltonian at 500 qubits from 1,036MB (Qiskit) to 142MB, a 7.3 times reduction that directly enables larger problem sizes within a fixed memory budget. PauLIB is open source and provides C++ and Python interfaces.