A transcriptomics-native foundation model for universal cell representation and virtual cell synthesis
A transcriptomics-native foundation model for universal cell representation and virtual cell synthesis
Jiang, X.; Xie, J.
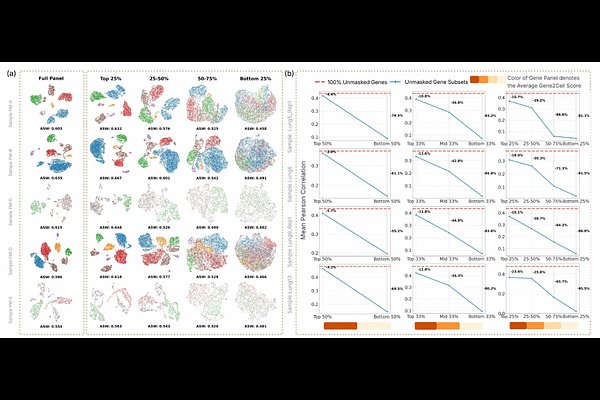
AbstractCurrent single-cell foundation models rely on language-model architectures that ignore transcriptomic data distributions, often underperforming specialized methods. We introduce xVERSE, a transcriptomics-native foundation model coupling batch-invariant representation learning with the probabilistic generation of expression profiles. xVERSE outperforms the leading foundation and batch-effect correction methods in representation learning by 17.9% and 11.4%, respectively, successfully preserving biological heterogeneity while diminishing batch effects. Furthermore, xVERSE surpasses the second-best spatial imputation method by 34.3% and uniquely synthesizes virtual cells indistinguishable from biological data (AUROC {approx} 0.5). As a powerful data-augmentation engine, xVERSE utilizes these high-fidelity virtual cells to enable accurate clustering and marker detection in tiny datasets -- resolving rare cell types with as few as four cells -- while improving the generalizability of cross-modality predictions across diverse pathological states. These results establish xVERSE as a transformative framework unlocking analytical capabilities beyond conventional models.