Multi-model reinforcement learning with online retrospective change-point detection
Multi-model reinforcement learning with online retrospective change-point detection
Chartouny, A.; Khamassi, M.; Girard, B.
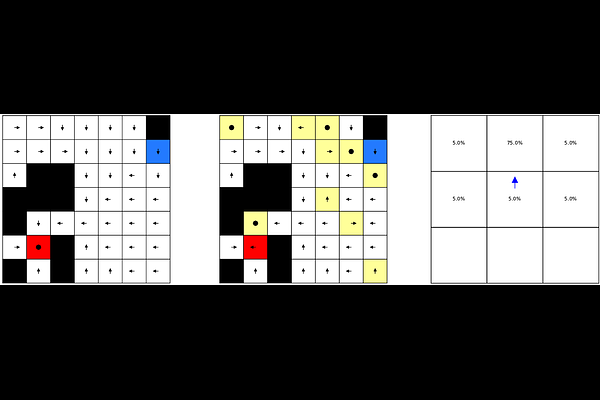
AbstractUnlike humans, who continuously adapt to both known and unknown situations, most reinforcement learning agents struggle to adjust to changing environments. In this paper, we present a new model-based reinforcement learning method that adapts to local task changes online. This method can detect changes at the level of the state-action pair, create new models, retrospectively update its models depending on when it estimates that the change happened, reuse past models, merge models if they become similar, and forget unused models. This new change detection method can be applied to any Markov decision process, to detect changes in transitions or in rewards. Arbitrating between local models limits memory costs and enables faster adaptation to new contexts which sub-parts have been experienced before. We provide a thorough analysis of each parameter of the multi-model agent and demonstrate that the multi-model agent is stable and outperforms single-model methods in uncertain environments. This novel multi-model agent yields new insights and predictions concerning optimal decision-making in changing environments, which could in turn be tested by future experiments in humans.