A Self-Supervised Foundation Model for Robust and Generalizable Representation Learning in STED Microscopy
A Self-Supervised Foundation Model for Robust and Generalizable Representation Learning in STED Microscopy
Bilodeau, A.; Beaupre, F.; Chabbert, J.; Bellavance, J.-M.; Lessard, K.; Deschenes, A.; Bernatchez, R.; De Koninck, P.; Gagne, C.; Lavoie-Cardinal, F.
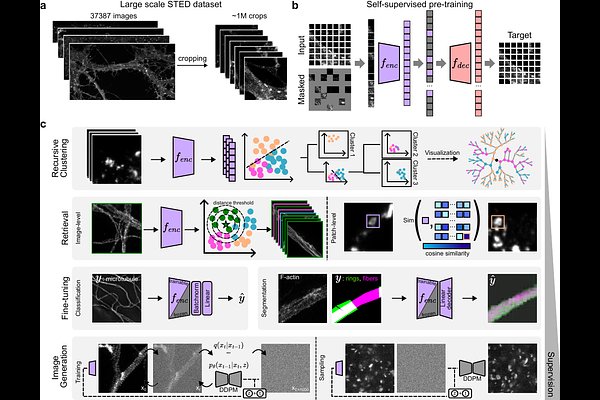
AbstractFoundation Models (FMs) have drastically increased the potential and power of deep learning algorithms in the fields of natural language processing and computer vision. However, their application in specialized fields like biomedical imaging, and fluorescence microscopy remains difficult due to distribution shifts, and the scarcity of high-quality annotated datasets. The high cost of data acquisition and the requirement for in-domain expertise further exacerbate this challenge in super-resolution microscopy. To address this, we introduce STED-FM, a foundation model specifically designed for super-resolution STimulated Emission Depletion (STED) microscopy. STED-FM leverages a Vision Transformer (ViT) architecture trained at scale with Masked Autoencoding (MAE) on a new dataset of nearly one million STED images. STED-FM learns expressive latent representations without extensive annotations. Our comprehensive evaluation demonstrates STED-FM\'s versatility across diverse downstream tasks. Unsupervised experiments highlight the discriminative nature of its learned latent space. Our model significantly reduces the need for annotated data required to achieve strong performance in classification and segmentation tasks, both in- and out-of-distribution. Furthermore, STED-FM enhances diffusion-model-generated images, enabling latent attribute manipulation and the discovery of novel and subtle nanostructures and phenotypes. Its structure retrieval capabilities are also integrated into automated STED microscopy acquisition pipelines. Its high expressivity across numerous tasks make STED-FM a highly valuable resource for researchers analyzing super-resolution STED images.